負責任 AI 設計
根據官方文件,一個負責任 AI 的產品設計有以下幾個核心維度,以下是每個項目的詳細介紹與說明:
1. 公平 (Fairness)
定義:公平是指 AI 系統在運作過程中不會對特定群體或個體產生不正當的偏見或歧視。這包括對不同性別、種族、年齡、社會經濟背景或其他身份特徵的公平對待。
詳細說明:
- AI 系統應該確保其輸出不會基於這些敏感屬性(如種族、性別等)進行不公平的區分或歧視。
- 需要對訓練數據進行審查,確認是否存在偏見或不平衡的問題,並採取措施以減少這些偏見。
- 通過公平算法或公平評估指標來監控和調整模型的行為,確保其對所有利害關係人的影響是一致的,並且不會造成不公平的後果。
以 Amazon Transcribe – Batch (English-US) 為例子,他們在訓練語言基礎模型時即考量到公平性,故考量到各個區域定義的演講者社群,例如中西部或紐約市,以及由身分的多個維度 (包括祖先、年齡和性別) 定義的社群,盡可能讓訓練資料涵蓋各種混雜因素下廣泛類型的人類演講者,以使模型在美國英語演講者可能使用的各種發音、語調、詞彙和語法特徵方面都能很好地發揮作用。
2. 可解釋 (Explainability)
定義:可解釋性是指 AI 系統的行為和決策可以被理解和追蹤,以便利害關係人能夠解釋和評估系統的輸出。
詳細說明:
- 人類需要能夠理解 AI 系統是如何做出特定決策的,尤其是在涉及高風險領域(如醫療、金融等)時,理解背後的邏輯尤為重要。
- 提供可解釋性有助於增強信任,並能在出現錯誤或不合適的結果時,找到原因並進行調整。
- 這可以通過開發“可解釋模型”或提供決策過程的可視化來實現。
以 Amazon Transcribe 為例子,當其記錄音訊時,它會為同一記錄建立不同的版本,並為每個版本指派置信度分數。如果客戶啟用替代記錄,Amazon Transcribe 會傳回置信度較低的記錄的替代版本。客戶可以探索替代的記錄,以更深入了解為每個音訊輸入產生的候選字詞和片語。
Amazon SageMaker Clarify
Amazon SageMaker Clarify 可以在幾分鐘內評估基礎模型 (FM)、建置對 ML 模型的信任、可存取的科學指標和報告、支援合規計畫。除此之外,他也可以透過以下方式實現模型解釋性(explainability):
- 特徵歸因(Feature Attribution):SageMaker Clarify 使用 Shapley 值等方法來解釋模型預測的依據,這有助於了解哪些特徵對模型的預測有影響,進而解釋模型如何做出決策。Shapley 值能夠衡量每個特徵對預測結果的貢獻,幫助理解模型的運作邏輯。
- 偏誤檢測(Bias Detection):SageMaker Clarify 可以在訓練前後以及模型部署後檢測數據和模型中的偏誤,這有助於識別訓練數據中可能存在的偏誤,並在模型預測過程中檢測和解釋可能的偏誤。這樣的功能對於減少模型中的不公平性和提升透明度至關重要。
- 偏誤度量與分析報告:SageMaker Clarify 可生成偏誤度量指標,並提供可視化報告,這些報告有助於監控模型預測是否受到偏誤的影響,並為風險與合規團隊提供所需的治理報告。
- 模型監控:SageMaker Clarify 還能夠在模型部署後,對特徵貢獻的變化進行監控,這有助於檢測模型在生產環境中的解釋性是否發生漂移。這樣的監控可以及時發現模型在實際運行中的不穩定性或不公平性。
- 增進可解釋性與合規性:透過模型解釋,SageMaker Clarify 使得模型預測結果對外部監管機構、業務決策者及開發人員更具透明度,特別是在需要解釋模型預測原因的領域(如金融服務、醫療、教育等)。
- 支持多階段分析:SageMaker Clarify 可以在機器學習流程的不同階段進行分析,包括訓練前、訓練後和生產環境中,幫助開發者在整個生命周期中理解模型行為,並進行必要的調整以減少偏誤和增強解釋性。
3. 隱私權與安全性 (Privacy and security)
定義:隱私和安全性確保資料在取得、使用和儲存過程中不會被濫用,並且符合隱私保護的法律和規範。
詳細說明:
- 確保 AI 系統在收集、處理和分析個人數據時遵循相關法律法規(如 GDPR 等隱私保護法律)。
- 需要加強對資料存取的控制,並加密敏感資料,防止數據洩露或遭到濫用。
- AI 系統應該能夠在不危害用戶隱私的情況下提供有效的服務,並設有適當的資料刪除機制。
4. 安全 (Safety)
定義:安全是防止 AI 系統的運行或其輸出對使用者、環境或社會造成潛在的危害。
詳細說明:
- 確保 AI 系統在任何情況下都不會造成物理、心理或社會的傷害,特別是在敏感領域如醫療、自駕車等。
- 需要對系統進行反覆測試和監控,識別可能的風險點並採取預防措施。
- 這包括制定緊急關閉或修正的機制,以應對突發的系統失效或錯誤。
5. 可控 (Controllability)
定義:可控性確保對 AI 系統的行為可以進行有效的監控和指導,確保其依照預期運作。
詳細說明:
- AI 系統應該設有適當的監控和反饋機制,以便操作員或管理者能夠對其行為進行調整。
- 可控性也意味著可以在需要時對系統進行干預,確保其不會進行偏離預期的行為。
- 這可以通過設立警報系統、設置自動檢查點和人類監督機制來實現。
Amazon SageMaker Clarify 和 Fmeval 都可以用來作為模型評估,
6. 準確與穩健 (Veracity and robustness)
定義:準確性和穩健性是指 AI 系統能夠在不同情況下穩定、準確地輸出結果,並能應對異常或不規則的輸入。
詳細說明:
- AI 系統必須能夠在各種情況下準確運作,即使面對不完整、不一致或噪聲數據,依然能提供有價值的結果。
- 穩健性意味著系統在遇到未預見的情況時,仍能保持正常運作,而不會崩潰或產生錯誤結果。
- 這需要對系統進行充分的測試,並設計防止系統失敗的機制。

7. 管控 (Governance)
定義:管控是指將最佳實踐和合規標準納入 AI 供應鏈,包括對開發者、部署者及其使用者的指導和監管。
詳細說明:
- 確保 AI 開發和部署遵循行業標準、法律法規和倫理準則,並對其進行嚴格的監管。
- 包括選擇和管理供應商的標準,確保供應商提供的技術符合負責任 AI 的要求。
- 強調對 AI 系統全生命周期的管控,從開發到部署,直到系統退役。
Amazon SageMaker 的 ML 治理 (ML Governance)
ML 治理 是指對機器學習(ML)模型的管理、監控、合規性、風險管理和持續優化的一整套機制。在 SageMaker 中,這一概念是通過多種功能和服務來實現的,主要包括:
- 模型生命周期管理:SageMaker 提供了端到端的模型管理功能,幫助企業管理模型的開發、訓練、部署和監控等各個階段。通過這些功能,企業能夠確保模型在整個生命週期中的合規性和安全性。
- 模型訓練與版本控制:SageMaker 能夠對模型進行版本控制,並提供詳細的訓練記錄,讓使用者能夠追蹤模型的訓練過程、數據集、超參數設定等重要信息。這有助於確保模型的可追溯性,並防止錯誤或無法解釋的決策。
- 安全與合規性:SageMaker 提供強大的安全功能,包括加密、權限管理和審計功能。這些功能可以幫助企業遵守資料隱私和合規性要求(如 GDPR),並保護敏感資料不被未經授權的使用。
- 監控與評估:使用 SageMaker,可以對模型的表現進行持續監控,進而評估其在實際運行中的效果。若發現問題,能夠快速進行調整或重新訓練,以避免模型產生偏見或錯誤的結果。
SageMaker Model Cards
SageMaker Model Cards 是一種專門用來描述和文檔化 ML 模型的工具,旨在提供模型開發過程中關鍵資訊的透明度和可追溯性。這些卡片可以幫助企業管理、跟踪和審查每個模型的使用情況,並在實現管控(Governance)方面起到以下作用:
- 模型描述:Model Cards 包含了模型的詳細描述,包括模型的目的、適用範圍、訓練數據的來源與質量、開發過程中使用的技術和方法等。這些信息可以幫助監管機構、開發者和使用者理解模型的背景和運行條件,確保其符合道德和合規性要求。
- 風險評估:Model Cards 中還包括風險評估部分,詳細列出模型可能的風險點(如偏見、數據不完整等)。這有助於開發者在部署前進行風險控制,並及時采取措施來降低風險。
- 性能指標:模型卡片還會列出模型在不同場景下的表現和效果,包括精確度、召回率等性能指標。這能夠幫助利害關係人評估模型的可靠性和有效性。
- 透明性與合規性:Model Cards 的透明化文檔有助於增強對 AI 系統的信任,並使企業能夠遵守相關的法律法規和道德規範。這為合規性檢查提供了必要的文檔支持。
資料治理 data governance
資料控管包括確保資料處於適當狀態以支援業務計畫和營運的程序和政策。現代組織大規模收集來自各種來源的資料,以增強營運和服務交付。但是,資料驅動型決策只有在資料符合所需品質和完整性標準時才有效。
資料控管決定資料使用的角色、責任和標準。概述了誰可以根據什麼資料、使用什麼方法以及在什麼情況下採取什麼動作。隨著越來越多的資料用於支援人工智慧 (AI) 和機器學習 (ML) 使用案例,所有資料使用都滿足監管和道德要求變得至關重要。資料控管平衡資料安全與戰術和策略目標,以確保最大效率。
資料治理的策略包含了資料生命週期、日誌紀錄、位置紀錄、監控、觀察、保留
分析管控
分析管控既可管控用於分析應用程式的資料,也可以管控分析系統的使用情況,例如分析報告版本控制和文件。與往常一樣,追蹤法規要求,制定公司政策,並為更廣泛的組織提供防護機制。
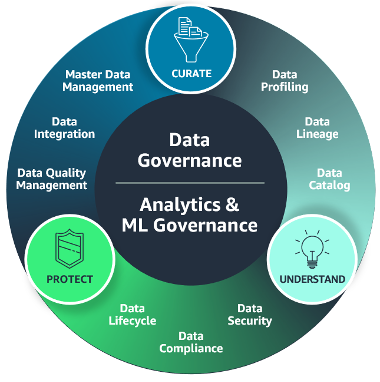
8. 透明 (Transparency)
定義:透明性是指讓利害關係人了解 AI 系統的運作方式和決策過程,幫助他們做出明智的選擇。
詳細說明:
- 透明性意味著系統設計、開發和運營過程中的關鍵資訊應該對相關利害關係人開放,讓他們理解 AI 系統如何處理數據、做出決策和執行任務。
- 利害關係人(如使用者、監管機構等)應該能夠輕鬆訪問有關系統運作的信息,並能夠對其功能、風險和效益做出充分的了解。
- 透明的設計可以增加信任,幫助確保系統的道德和合規性。
這些核心維度共同促進了 AI 系統的負責任設計和運營,確保它們在實現技術創新的同時,也能夠考慮到社會、法律和道德的各種要求。
AI 解決方案的安全性、合規性和治理
安全與合規是 AWS 和客戶的共同責任。此共同模型有助於減輕客戶的操作負擔,因為從託管作業系統和虛擬化層的元件到服務運作的設施實體安全性都由 AWS 操作、管理和控制。客戶負責和管理訪客作業系統 (包含更新和安全性修補程式)、其他相關應用程式軟體,以及 AWS 提供的安全群組防火牆組態。
AWS 的資料保護及隱私權 Security
雲端安全是 AWS 和客戶的共同的責任。可以透過以下服務提升安全性
- Amazon GuardDuty
- AWS Nitro System -核心安全性、機密性和合規性要求的能力。我們所設計的 Nitro System 具備工作負載保密功能,連操作者都無法存取。Nitro System 沒有可讓任何系統或人員登入 EC2 伺服器、讀取 EC2 執行個體的記憶體或存取執行個體儲存體上所存任何資料的機制,亦無法存取加密 EBS 磁碟區上所存的任何資料。
- AWS CloudHSM 和 AWS Key Management Service : 安全地產生和管理加密金鑰
- AWS Config 和 AWS CloudTrail : 提供監控和記錄功能,以實現合規與稽核效果。
資料主權 Data sovereignty
您可以選擇將您的客戶資料存放在我們全球任何一個或多個 AWS 區域中。 使用 AWS 服務時,您也可以確信您的客戶資料就放置在您所選取的 AWS 區域中。有小部分 AWS 服務涉及資料傳輸,例如,為了開發和改善特定服務,在這種情況下您可以選擇退出傳輸;或者因為傳輸本身就是服務的主要部分 (例如內容交付服務)。我們禁止且我們的系統旨在防止 AWS 人員出於任何目的 (包括服務維護) 從遠端存取客戶資料,除非您自己要求存取,或除非防止欺詐和濫用或是為了遵守法律而需要存取。如果我們收到執法申請,且假若申請與法律衝突、過於廣泛或我們有其他適當的理由這樣做,我們將質疑政府機構有關客戶資料的執法申請。我們還提供雙年度資訊申請報告,描述 AWS 從執法部門收到的資訊申請的類型和數量。
資料隱私權 Data privacy
藉助各種服務和功能,我們不斷提高隱私保護的標準,讓您可以實作自己的隱私控制,包括進階存取、加密和日誌記錄功能。我們可以使用 AWS 受管或由您全受管的金鑰輕鬆加密傳輸中資料和靜態資料。您可以使用自己在 AWS 外部產生和管理的金鑰。我們實作穩定且可擴展的流程來 管理隱私權,包括如何收集、使用、存取、存放和刪除資料。我們提供了各種最佳實務文件、培訓和指引,您可以利用這些來保護您的資料,例如 AWS Well-Architected Framework 的安全性支柱。我們僅根據您的書面指示處理客戶資料,即您上傳到您的 AWS 帳戶的任何個人資料,並且不會在未經您同意的情況下存取、使用或分享您的資料,除非為防止詐騙和濫用或遵守法律,如我們的 AWS 客戶協議和 AWS GDPR 資料處理增補合約中所述。成千上萬的客戶須遵守 歐盟《一般資料保護規範》(GDPR)、 PCI 和 HIPAA,且將使用 AWS 服務處理這些類型的工作負載。AWS 已獲得多項國際認可的認證和資格鑑定,證明符合嚴格的國際標準,例如適用於雲端安全的 ISO 27017、適用於隱私資訊管理的 ISO 27701,和適用於雲端隱私的 ISO 27018。我們不會將客戶資料或從中衍生的資訊用於行銷或廣告。
資料控制與常駐 Data controls and residency
藉助 AWS,您可以使用功能強大的 AWS 服務和工具來控制您的資料,包括確定資料的儲存位置、保護方式以及存取人員。AWS Identity and Access Management (IAM) 等服務可讓您安全地管理對 AWS 服務與資源的存取。AWS CloudTrail 和 Amazon Macie 支援合規、偵測及稽核,而 AWS CloudHSM 和 AWS Key Management Service (KMS) 可讓您安全地產生和管理加密金鑰。AWS Control Tower 可管控資料落地。
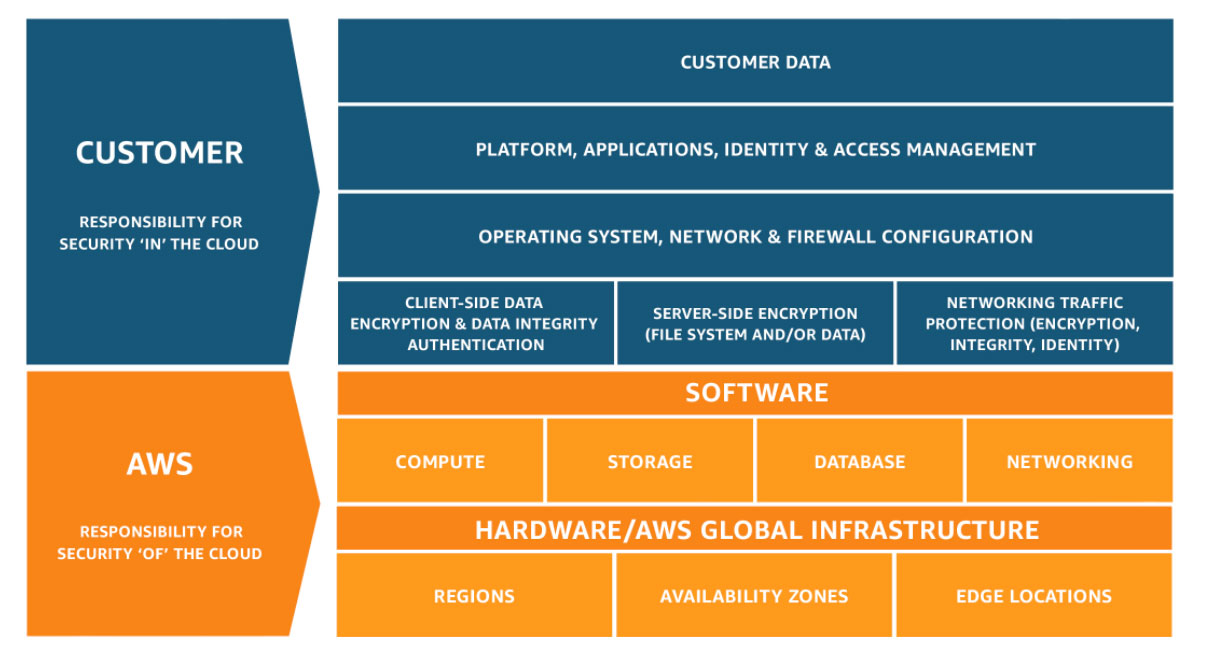
共享責任模型(Shared Responsibility Model)
AWS 負責「雲端本身的安全」– AWS 負責保護執行 AWS 雲端提供的所有服務的基礎設施。此基礎設施由執行 AWS 雲端服務的硬體、軟體、聯網與設施組成。
客戶負責「雲端內部的安全」– 客戶的責任由自行選擇的 AWS 雲端服務決定。這會決定客戶在安全責任中必須執行的組態工作量。例如,Amazon Elastic Compute Cloud (Amazon EC2) 等服務分類為基礎設施即服務 (IaaS),因此,需要客戶執行所有必要的安全組態和管理任務。部署 Amazon EC2 執行個體的客戶需負責管理訪客作業系統 (包含更新和安全性修補程式)、客戶在執行個體上安裝的所有應用程式軟體或公用程式,以及 AWS 在每個執行個體提供的防火牆組態 (稱為安全群組)。 若是 Amazon S3 和 Amazon DynamoDB 等抽象服務,AWS 運作基礎設施層、作業系統和平台,客戶則存取端點以儲存及擷取資料。客戶負責管理其資料(包括加密選項),對其資產進行分類,以及使用 IAM 工具來套用適當的權限。
簡單而言,AWS 將安全性的責任分為:
- AWS 責任 (Security of the Cloud):
- 物理基碼資料中心的安全性
- 全球基礎架構保護
- 合規性與標準維護
- 客戶責任 (Security in the Cloud):
- 資料加密 (Data Encryption at Rest & In Transit)
- 安全性群組 (Security Groups) 設定
- IAM 存取控制與身份管理
- 應用程式與數據保護
- 共同的責任
- 修補程式管理 – AWS 負責基礎設施內的漏洞修補和修正,但客戶需負責修補自己的訪客作業系統和應用程式。
- 組態管理 – AWS 負責維護其基礎設施裝置的組態,而客戶負責設定自己的訪客作業系統、資料庫和應用程式。
- 感知與培訓 – AWS 訓練 AWS 員工,而客戶必須訓練自己的員工。
只要使用third-party,雙方都要共同承擔風險
題目
Q28
An AI company periodically evaluates its systems and processes with the help of independent software vendors (ISVs). The company needs to receive email message notifications when an ISV’s compliance reports become available.
Which AWS service can the company use to meet this requirement?
- AWS Audit Manager
- AWS Artifact
- AWS Trusted Advisor
- AWS Data Exchange
AWS Artifact 是 AWS 提供的合規性與稽核報告存取平台,它提供 AWS 的 第三方審查報告(如 ISO、SOC、PCI 等)、支援使用者 訂閱報告更新通知(例如:新版本出現時收到 email 通知)、可與 AWS Organizations 整合,方便多帳號企業管理。
A. AWS Audit Manager 幫助你自己建立內部合規框架與報告。用於產生自家帳戶內部的合規資料,不提供第三方報告下載或通知。
C. AWS Trusted Advisor 提供帳戶最佳實踐建議(成本、安全、性能等)。
D. AWS Data Exchange 用來訂閱並使用第三方數據集(非合規報告)。
Q43
Which functionality does Amazon SageMaker Clarify provide?
- Integrates a Retrieval Augmented Generation (RAG) workflow
- Monitors the quality of ML models in production
- Documents critical details about ML models
- Identifies potential bias during data preparation
(B) 屬於 SageMaker Model Monitor 的功能。(C) 是 SageMaker Model Card 的功能。
Q37
An AI practitioner is building a model to generate images of humans in various professions. The AI practitioner discovered that the input data is biased and that specific attributes affect the image generation and create bias in the model.
Which technique will solve the problem?
- Data augmentation for imbalanced classes
- Model monitoring for class distribution
- Retrieval Augmented Generation (RAG)
- Watermark detection for images
在處理不平衡類別的問題時,數據增強(Data Augmentation)可以幫助減少模型的偏見,並提升模型對少數類別的識別能力。例如:
- 圖像增強:如果處理的是圖像分類問題,可以使用旋轉、翻轉、縮放、剪裁、顏色變換等技術來生成新的樣本,這樣不僅能增強少數類別的樣本數量,還能提升模型的泛化能力。
- 文本增強:對於文本分類問題,可以使用同義詞替換、隨機刪除、插入或重排列等技術來創建多樣化的少數類別數據。
- 噪聲注入:對數據加上隨機噪聲(如隨機擾動、隨機裁剪等)可以幫助模型學會處理變化和不確定性,減少對單一樣本的過擬合。
Q54
A company wants to build an interactive application for children that generates new stories based on classic stories. The company wants to use Amazon Bedrock and needs to ensure that the results and topics are appropriate for children.
Which AWS service or feature will meet these requirements?
- Amazon Rekognition
- Amazon Bedrock playgrounds
- Guardrails for Amazon Bedrock
- Agents for Amazon Bedrock
Q78
An AI practitioner trained a custom model on Amazon Bedrock by using a training dataset that contains confidential data. The AI practitioner wants to ensure that the custom model does not generate inference responses based on confidential data.
How should the AI practitioner prevent responses based on confidential data?
- Delete the custom model. Remove the confidential data from the training dataset. Retrain the custom model.
- Mask the confidential data in the inference responses by using dynamic data masking.
- Encrypt the confidential data in the inference responses by using Amazon SageMaker.
- Encrypt the confidential data in the custom model by using AWS Key Management Service (AWS KMS).
如果訓練資料集中包含機密資料,那麼該資料可能已被納入模型的學習過程,進而影響推論結果。為了確保模型的推論結果不基於機密資料,AI 實踐者需要刪除該自訂模型,從原始訓練資料集中移除機密資料後,重新訓練模型。其他選項中的方法(例如 B、C、D)無法根本性地解決這個問題,因為這些方法無法消除模型在訓練期間已學習到的機密資料。
Q30
A company is using the Generative AI Security Scoping Matrix to assess security responsibilities for its solutions. The company has identified four different solution scopes based on the matrix.
Which solution scope gives the company the MOST ownership of security responsibilities?
- Using a third-party enterprise application that has embedded generative AI features.
- Building an application by using an existing third-party generative AI foundation model (FM).
- Refining an existing third-party generative AI foundation model (FM) by fine-tuning the model by using data specific to the business.
- Building and training a generative AI model from scratch by using specific data that a customer owns.
在生成式 AI 安全性範圍界定矩陣中,不同的解決方案範圍代表了企業在安全責任上的擁有程度。從最低到最高,當企業完全依賴第三方服務時,安全責任主要由服務提供商承擔;而當企業自己從頭建立並訓練模型時,則需要自行管理整個模型的生命週期,從數據處理、模型訓練到部署安全,都由企業全面負責。
Q87
A company wants to use Amazon Bedrock. The company needs to review which security aspects the company is responsible for when using Amazon Bedrock.
Which security aspect will the company be responsible for?
- Patching and updating the versions of Amazon Bedrock
- Protecting the infrastructure that hosts Amazon Bedrock
- Securing the company’s data in transit and at rest
- Provisioning Amazon Bedrock within the company network
Q128
A hospital is developing an AI system to assist doctors in diagnosing diseases based on patient records and medical images. To comply with regulations, the sensitive patient data must not leave the country the data is located in.
Which data governance strategy will ensure compliance and protect patient privacy?
- Data residency
- Data quality
- Data discoverability
- Data enrichment
- A. Data residency
- 資料駐留是指資料在特定地理位置存儲和處理的要求,這對於符合合規性要求尤其重要。許多國家或地區的法律規定敏感數據(如病患資料)必須保存在本地,不能傳輸到其他國家。因此,這是最能確保資料不離開存放國家的策略,並且對病患隱私的保護至關重要。
- B. Data quality
- 資料質量指的是確保資料的準確性、完整性和一致性,這對於AI系統的有效性很重要,但它並不直接解決資料是否能夠跨境流動的問題。因此,它對合規性和數據隱私的保護作用較小。
- C. Data discoverability
- 資料可發現性指的是讓資料在合適的情境下容易被發現和使用。這對於資料的搜索和存取非常有用,但並沒有直接與資料的地理位置或隱私保護有關,因此也無法解決資料不離開國家的問題。
- D. Data enrichment
- 資料豐富化是指在現有資料的基礎上增加額外的資料內容,這對於提升資料的價值和AI模型的表現有幫助,但與資料是否能跨國移動的合規性問題無關。
Q71
An accounting firm wants to implement a large language model (LLM) to automate document processing. The firm must proceed responsibly to avoid potential harms.
What should the firm do when developing and deploying the LLM? (Choose two.)
- Include fairness metrics for model evaluation.
- Adjust the temperature parameter of the model.
- Modify the training data to mitigate bias.
- Avoid overfitting on the training data.
- Apply prompt engineering techniques.
AC 選項可以實現模型的透明性 & 可解釋性
Q47
A social media company wants to use a large language model (LLM) for content moderation. The company wants to evaluate the LLM outputs for bias and potential discrimination against specific groups or individuals.
Which data source should the company use to evaluate the LLM outputs with the LEAST administrative effort?
- User-generated content
- Moderation logs
- Content moderation guidelines
- Benchmark datasets
A 選項代表用戶生成內容,雖具有真實性和多樣性,但它的行政工作量通常較高。因為社交平台的內容非常龐大且多變,篩選和標註這些內容可能需要大量的人力和時間。因此,這不太可能是最有效的選擇來減少行政工作。
B 選項的審查日志可以提供有關過去決策的詳細信息,但如果內容審查流程較為繁瑣或規模較大,這些日志資料可能會非常冗長,需要進行複雜的分析來識別偏見或歧視。因此,這也可能會增加行政負擔。
C 選項代表指導方針,決定了平台對於什麼樣的內容是被允許的,什麼樣的內容應該被過濾或刪除的規範,主要是對於決策標準化,並不直接提供用來評估模型輸出的數據。
D 選項是專門設計的數據集,用於評估機器學習模型的性能,通常包括標註了偏見或歧視情況的數據。
Q43
Which functionality does Amazon SageMaker Clarify provide?
- Integrates a Retrieval Augmented Generation (RAG) workflow
- Monitors the quality of ML models in production
- Documents critical details about ML models
- Identifies potential bias during data preparation
Amazon SageMaker Clarify 是 AWS 提供的一個工具,專門用來偵測和減少機器學習模型的偏見(bias),並提供可解釋性(explainability)的功能。它的主要用途包括:
- 在數據準備階段識別潛在偏見(如性別、種族等因素對預測結果的影響)
- 分析訓練後的模型偏見,確保模型公平性
- 提供模型可解釋性,幫助理解輸入特徵如何影響預測結果
B 選項監控生產環境中的 ML 模型品質通常由 Amazon SageMaker Model Monitor 負責,而不是 SageMaker Clarify。而 C 選項雖然 SageMaker Clarify 會提供解釋性報告,但「記錄模型關鍵細節」的工作通常由 Amazon SageMaker Model Registry 或其他 MLOps 工具完成,而不是 Clarify 的主要功能。
Q39
A medical company is customizing a foundation model (FM) for diagnostic purposes. The company needs the model to be transparent and explainable to meet regulatory requirements.
Which solution will meet these requirements?
- Configure the security and compliance by using Amazon Inspector.
- Generate simple metrics, reports, and examples by using Amazon SageMaker Clarify.
- Encrypt and secure training data by using Amazon Macie.
- Gather more data. Use Amazon Rekognition to add custom labels to the data.
Amazon Inspector 主要用於安全性掃描,例如識別 AWS 環境中的漏洞,確保基礎設施合規。
C 選項的 Amazon Macie 主要用於識別與保護敏感數據(如醫療記錄或個人身份資訊),確保數據安全性,但它並不涉及模型的可解釋性。
Q1
A company makes forecasts each quarter to decide how to optimize operations to meet expected demand. The company uses ML models to make these forecasts.
An AI practitioner is writing a report about the trained ML models to provide transparency and explainability to company stakeholders.
What should the AI practitioner include in the report to meet the transparency and explainability requirements?
- Code for model training
- Partial dependence plots (PDPs)
- Sample data for training
- Model convergence tables
透明度(transparency)和可解釋性(explainability)是讓非技術背景的利益相關者能夠理解模型決策的關鍵。因此,AI 實踐者應該提供解釋模型行為的視覺化工具,而部分依賴圖(Partial Dependence Plots, PDPs) 就是其中一種有效方法。PDPs 可以顯示輸入特徵如何影響預測結果,幫助利益相關者理解模型如何做出決策。例如,如果某個季度的需求預測高度依賴於經濟增長率,PDPs 可以直觀地展示這種關係。
A 選項這雖然提高了技術透明度,但對於大多數公司利益相關者(如高層管理人員、營運經理)來說,程式碼的可讀性較差,無法直觀解釋模型的行為。