生成式 AI 觀念介紹
生成式 AI(Generative AI)是一種能夠根據輸入的數據自動生成新內容的人工智慧技術,例如文字、圖像、音樂或程式碼。這類 AI 主要依賴大型機器學習模型來理解和產生類似人類創作的內容。在生成式 AI 中,以下幾個概念至關重要:
Tokens(字元或字詞)
在自然語言處理(NLP)中,Token 是 AI 解析與理解語言的基本單位。
- 字元級 Token:模型將輸入拆分為單個字母或符號。例如:「AI」會被視為「A」和「I」兩個 Token。
- 字詞級 Token:將單詞或詞組視為一個 Token。例如:「machine learning」可能被視為一個 Token,而不是兩個。
- 子詞級 Token(如 BPE、WordPiece):拆分成更小的語言單元,使 AI 可以更有效地處理新詞彙。例如:「unhappiness」可能被拆成「un」、「happiness」。
但其實每個模型的分詞方式都會有所不同,比方說我們可以到 OpenAI Tokenizer 比較同樣一句話,就能發現光是 gpt-4o 和 gpt-3 legacy 就具有分詞差異。


Embeddings(嵌入)
Embeddings 是將語言轉換為數學向量(vector)的一種方式,使 AI 能夠理解詞語的關聯性與語境。
- 每個詞語(Token)會被映射到一個高維度的向量空間,數值越相近,代表詞語之間的語意越相似。
- 例如:「king」和「queen」的向量會彼此接近,而「dog」和「cat」的向量也會有類似的關聯。
Foundation Models (FM)(基礎模型)
基礎模型 是大規模預訓練的 AI 模型,能夠執行多種任務,如文本生成、圖像辨識、程式碼生成等。
- 這些模型(如 GPT、BERT、DALL·E)是基於海量數據訓練的,然後可以針對特定應用微調(fine-tune)。
- 具有遷移學習(Transfer Learning)能力,能夠從廣泛的知識基礎中適應不同的任務。
inference
通常推論會拿來與模型的訓練做比較。在生成式人工智慧(GenAI)的語境中,inference(推論)指的是使用訓練好的模型來產生輸出的過程,也就是模型在接收到輸入後「推論」出對應的結果。例如對於語言模型(如 GPT)來說,inference 是你輸入一段提示(prompt)後,模型生成回應的過程。又或是說對於圖像生成模型(如 Stable Diffusion)而言,inference 是輸入一段文字描述後,模型生成圖片的過程。
舉個例子,假設輸入「寫一首關於春天的詩」,然後 GPT-4 回你一首詩。這整個從接收輸入 → 模型處理 → 回傳詩句的過程,就是一次 inference。更具體來說,inference 包含:
- 載入一個訓練完成的模型(模型參數已固定)
- 接收輸入(prompt、文字、圖片、聲音等)
- 經過模型內部的神經網路計算
- 輸出生成結果(文字、圖像、回應等)
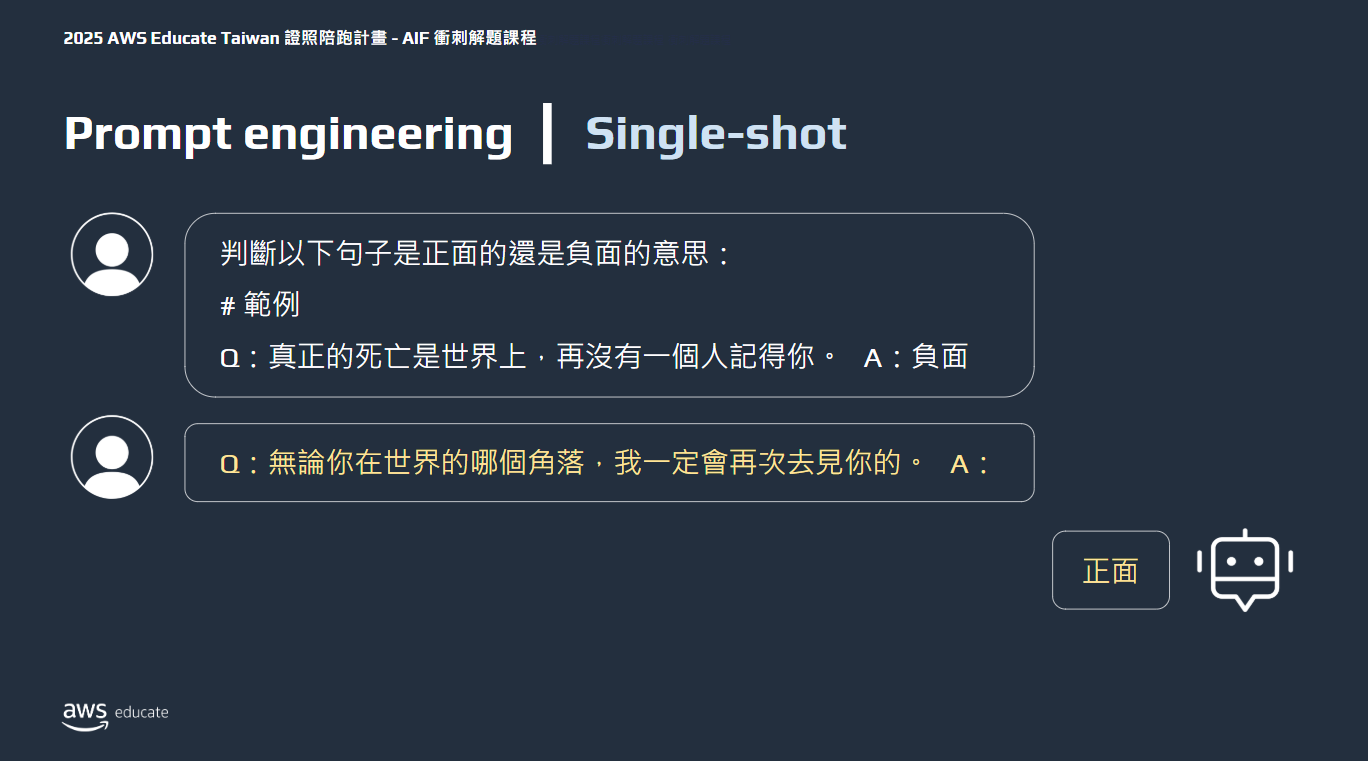
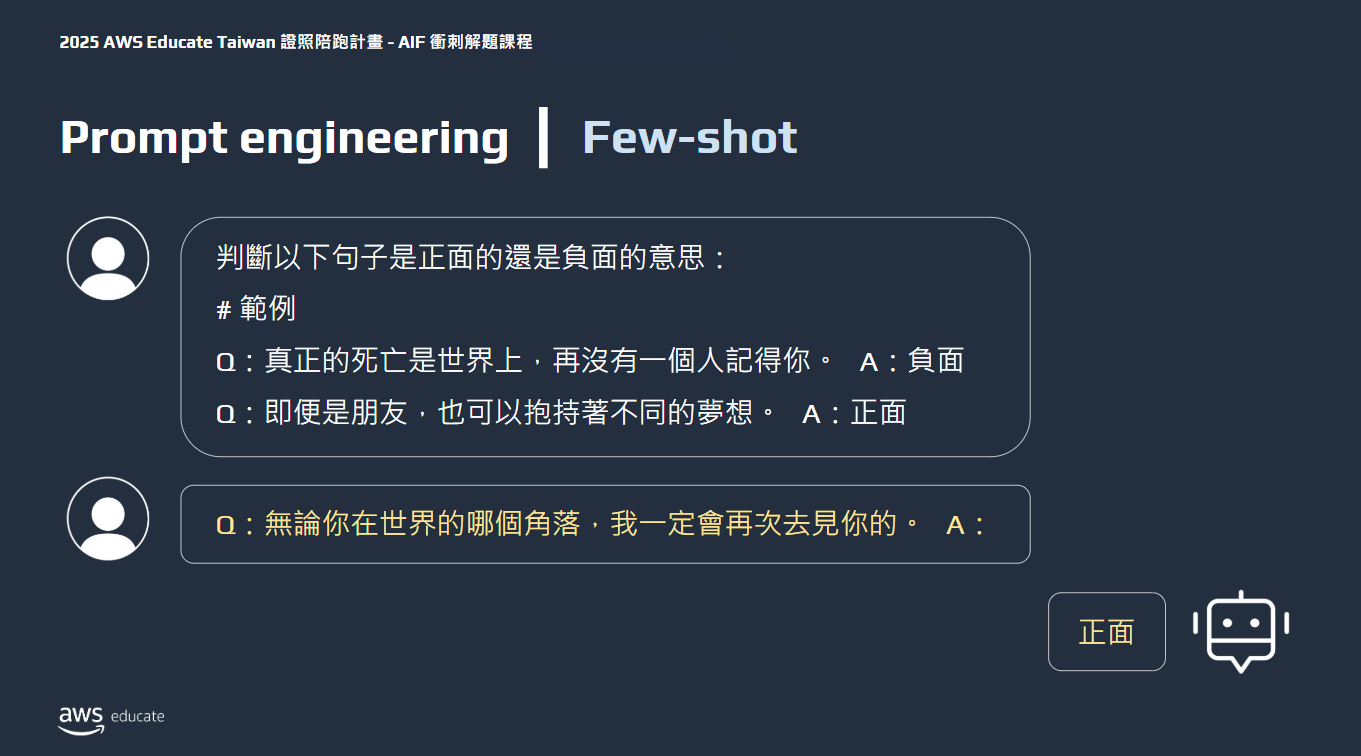
Prompt engineering
選擇有效的提示工程(Prompt engineering)
- zero shot
- single shot
- few shot
- Chain-of-Thought
- 讓模型在得到答案之前多思考一下


其他方式
- Negative Prompts
- Negative prompts 是在生成圖像時,明確告訴模型不要包含哪些元素或風格
- example
- Prompt: “A cat sitting on a beach”
- Negative Prompt: “blurry, distorted, low quality, text, watermark”
- Positive prompt
- 正常描述你想要的東西(例如 “a futuristic city”)。
- ambiguous prompts
- 含糊的 prompt 會增加生成圖像的隨機性,更容易導致無關圖片,完全與目標相反。
基礎模型(FM)應用的設計考量
基礎模型的訓練與微調(Fine-tuning)過程
評估基礎模型的性能
考題範例
Q63
Which term describes the numerical representations of real-world objects and concepts that AI and natural language processing (NLP) models use to improve understanding of textual information?
- Embeddings
- Tokens
- Models
- Binaries
答案是 (A),因為題目中說的是 numerical representations
Q82
What are tokens in the context of generative AI models?
- Tokens are the basic units of input and output that a generative AI model operates on, representing words, subwords, or other linguistic units.
- Tokens are the mathematical representations of words or concepts used in generative AI models.
- Tokens are the pre-trained weights of a generative AI model that are fine-tuned for specific tasks.
- Tokens are the specific prompts or instructions given to a generative AI model to generate output.
這題答案是 (A),而 (B)、(C)、(D) 分別代表 embeddings、weight 和 prompt
Q97
A company is using Retrieval Augmented Generation (RAG) with Amazon Bedrock and Stable Diffusion to generate product images based on text descriptions. The results are often random and lack specific details. The company wants to increase the specificity of the generated images.
Which solution meets these requirements?
- Increase the number of generation steps.
- Use the MASK_IMAGE_BLACK mask source option.
- Increase the classifier-free guidance (CFG) scale.
- Increase the prompt strength.
在 Stable Diffusion 中,CFG Scale 控制模型在圖像生成時要「多大程度上遵循提示(prompt)」。
- 低 CFG 值(如 3~5):生成圖像比較自由、創意高,但可能和 prompt 關聯較弱。
- 高 CFG 值(如 10~20):模型會更嚴格依照 prompt 的描述來生成圖像,具體性與可控性更強。
A. Increase the number of generation steps 增加步數(如從 25 → 50)會提高圖像質量與細節,但對於「是否忠於 prompt」的影響較小。
B. Use the MASK_IMAGE_BLACK mask source option 這是用在 圖像修補(inpainting) 情境下的 mask 設定,與從文字生成整圖(text-to-image)無關。
Q73
A company has documents that are missing some words because of a database error. The company wants to build an ML model that can suggest potential words to fill in the missing text.
Which type of model meets this requirement?
- Topic modeling
- Clustering models
- Prescriptive ML models
- BERT-based models
這屬於典型的 填空(Fill-in-the-blank)任務,又稱為 Masked Language Modeling(MLM),而這正是 BERT(Bidirectional Encoder Representations from Transformers) 模型的設計核心。
A. Topic modeling 用來找出文本中的主題(如 LDA),Clustering models 是無監督學習,用來分群資料,C. Prescriptive ML models 是一種較模糊的說法,指給出「最佳決策建議」的模型(如最佳路徑、最優資源分配)