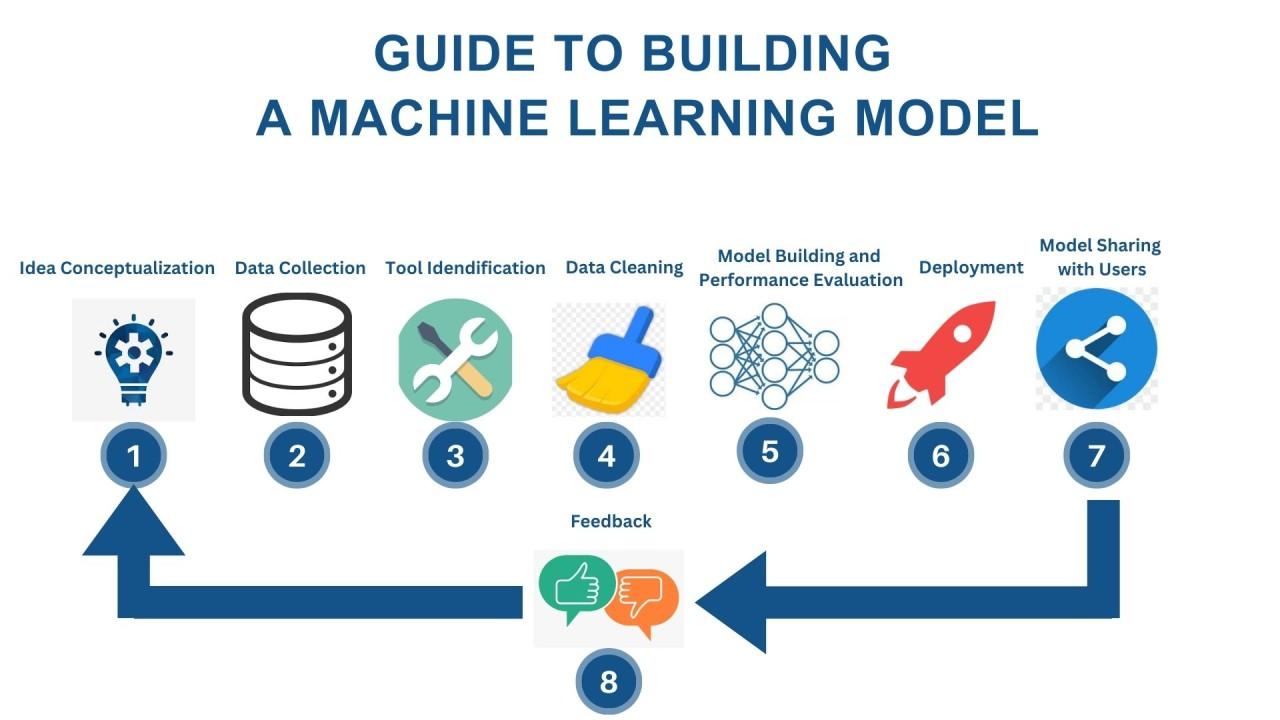
網路上有關模型開發的流程說明都大同小異,大致上可以分成以下幾個步驟
機器學習模型設計流程
隨著人工智慧(AI)技術的進步,機器學習(ML)模型已廣泛應用於各個領域,如影像辨識、自然語言處理和預測分析等。本文將介紹機器學習模型設計的基本流程,幫助讀者理解從資料準備到模型部署的各個步驟。
Step 1: 訓練資料收集
機器學習模型的核心是數據,因此第一步驟是收集適當的訓練資料。這些資料可以包括:
- 圖片:用於影像辨識、物件偵測等應用。
- 文字:適用於自然語言處理(NLP)、情感分析等任務。
資料的品質與多樣性將直接影響模型的效能,因此在這個階段,需確保數據的完整性與代表性。
Step 2: 資料清理
收集到的原始資料通常包含雜訊、不完整資訊或重複數據,因此必須進行資料清理。此步驟包含:
- 去除遺漏值與異常值,確保數據完整性。
- 標準化與正規化,使數據在相同尺度範圍內。
- 資料增強(Data Augmentation),如對影像進行旋轉、翻轉等操作,以提高模型的泛化能力。
Step 3: 模型訓練
在資料準備完善後,即可進行模型訓練。此步驟包括:
- 選擇適合的演算法,如深度學習中的 CNN(卷積神經網絡)適用於圖像處理,而 RNN(循環神經網絡)適用於文字分析。
- 設定超參數,如學習率、批次大小等,以影響模型的收斂速度與準確性。
- 模型訓練與調整,透過多次訓練與驗證來最佳化模型。
Step 4: 模型部署與推論
當模型訓練完成並達到滿意的效果後,下一步是將模型部署到實際應用環境,以提供推論服務。部署方式包括:
- 雲端部署:使用 AWS、Google Cloud、Azure 等雲端平台。
- 本地端部署:適用於對安全性要求較高的企業內部環境。
- 邊緣運算(Edge Computing):將模型運行於 IoT 裝置或手機等設備上。
模型部署(Model Deployment)
模型部署是指將訓練好的模型整合到生產環境,使其能夠被應用程式或服務使用。這通常涉及:
- 模型封裝:將模型轉換為 API 或嵌入應用程式。
- 負載均衡:確保多個使用者請求能夠有效處理。
- 監控與維護:持續追蹤模型的效能,及時修正錯誤。
模型推論(Model Inferencing)
推論是指根據輸入數據,利用已訓練好的模型產生預測結果的過程。這就好比說想像你是一家咖啡店的老闆,並且聘請了一位非常有經驗的咖啡師(機器學習模型),這時候我們要怎麼確定這位咖啡師真的 “很有經驗” 呢? 這時候我們就可以透過模型推論的概念,也就是當顧客點單(輸入數據)時,咖啡師迅速根據過去的經驗(已訓練好的模型),判斷最佳的咖啡配方,並沖泡出符合顧客口味的咖啡(預測結果)。
高效的推論系統需要:
- 低延遲與高吞吐量:確保即時回應,例如在自動駕駛或醫療診斷中。
- 資源優化:利用 GPU、TPU 或其他加速器來提高計算效率。
- 可擴展性:確保系統能夠應對大量請求,例如推薦系統或聊天機器人。
模型訓練 vs 模型推論
雖然兩者都是輸入樣本到模型中,並由模型產生預測結果,但模型訓練是開發階段,而模型推論是應用階段,且推論要求低延遲與高效率,和訓練不同。
舉個例子,可以想像模型訓練(Model Training)是你在學習煮咖啡,過程如下:
- 你試著用不同的咖啡豆、不同的水溫、不同的沖泡方式來製作咖啡。
- 每次做完後,你請朋友品嚐,並給你反饋(類似於計算損失函數)。
- 根據反饋,你不斷調整做法(類似於調整模型參數)。
- 經過數百次練習後,你學會了最完美的沖泡方式。
而模型推論則是你已經是一名專業咖啡師,當顧客點單時:
- 你根據顧客的需求(輸入數據),直接用你熟悉的方法沖泡咖啡(執行推論)。
- 這個過程不需要重新學習,只需要運用你已經掌握的技巧來製作咖啡(使用訓練好的模型來做預測)。
- 每次製作咖啡的時間很短(推論速度快)。
Step 5: 驗證與分析
模型上線後,需持續監控其效能,以確保其準確性與穩定性。驗證與分析的工作包括:
- 模型評估:透過混淆矩陣、精確率、召回率等指標評估模型表現。
- 錯誤分析:找出模型預測錯誤的原因,進行修正與優化。
- 模型更新:根據新數據重新訓練或微調模型,以適應環境變化。
Q36
A company built a deep learning model for object detection and deployed the model to production.
Which AI process occurs when the model analyzes a new image to identify objects?
- Training
- Inference
- Model deployment
- Bias correction
選 (B),因為有提到已經 deployed 模型
Q123
Which technique can a company use to lower bias and toxicity in generative AI applications during the post-processing ML lifecycle?
- Human-in-the-loop
- Data augmentation
- Feature engineering
- Adversarial training
Human-in-the-loop 透過在機器學習生命週期中(特別是在後處理階段)納入人類回饋,以降低偏見和有害內容的風險。此方法允許人類審查、介入並修正 AI 系統生成的輸出,確保公平性、減少偏見行為,並減輕有害或具攻擊性的內容,從而提升 AI 應用的可靠性與道德標準,屬於 human-centered design for explainable AI 範疇
B 選項雖然可以幫助增加數據集的多樣性,並減少由於不平衡數據所造成的偏見。然而,數據增強主要是在訓練階段使用,並不直接作用於後處理階段來減少生成內容中的偏見或毒性。
Q72
A company is building an ML model. The company collected new data and analyzed the data by creating a correlation matrix, calculating statistics, and visualizing the data.
Which stage of the ML pipeline is the company currently in?
- Data pre-processing
- Feature engineering
- Exploratory data analysis
- Hyperparameter tuning
Q70
Which strategy evaluates the accuracy of a foundation model (FM) that is used in image classification tasks?
- Calculate the total cost of resources used by the model.
- Measure the model’s accuracy against a predefined benchmark dataset.
- Count the number of layers in the neural network.
- Assess the color accuracy of images processed by the model.
Q11
A company wants to build an ML model by using Amazon SageMaker. The company needs to share and manage variables for model development across multiple teams.
Which SageMaker feature meets these requirements?
- Amazon SageMaker Feature Store
- Amazon SageMaker Data Wrangler
- Amazon SageMaker Clarify
- Amazon SageMaker Model Cards
Amazon SageMaker Feature Store 是一個中心化的特徵資料庫,Amazon SageMaker Data Wrangler,用於資料前處理與轉換(如清洗、轉換欄位格式),幫你「準備特徵」,但不是用來管理與共用特