機器學習
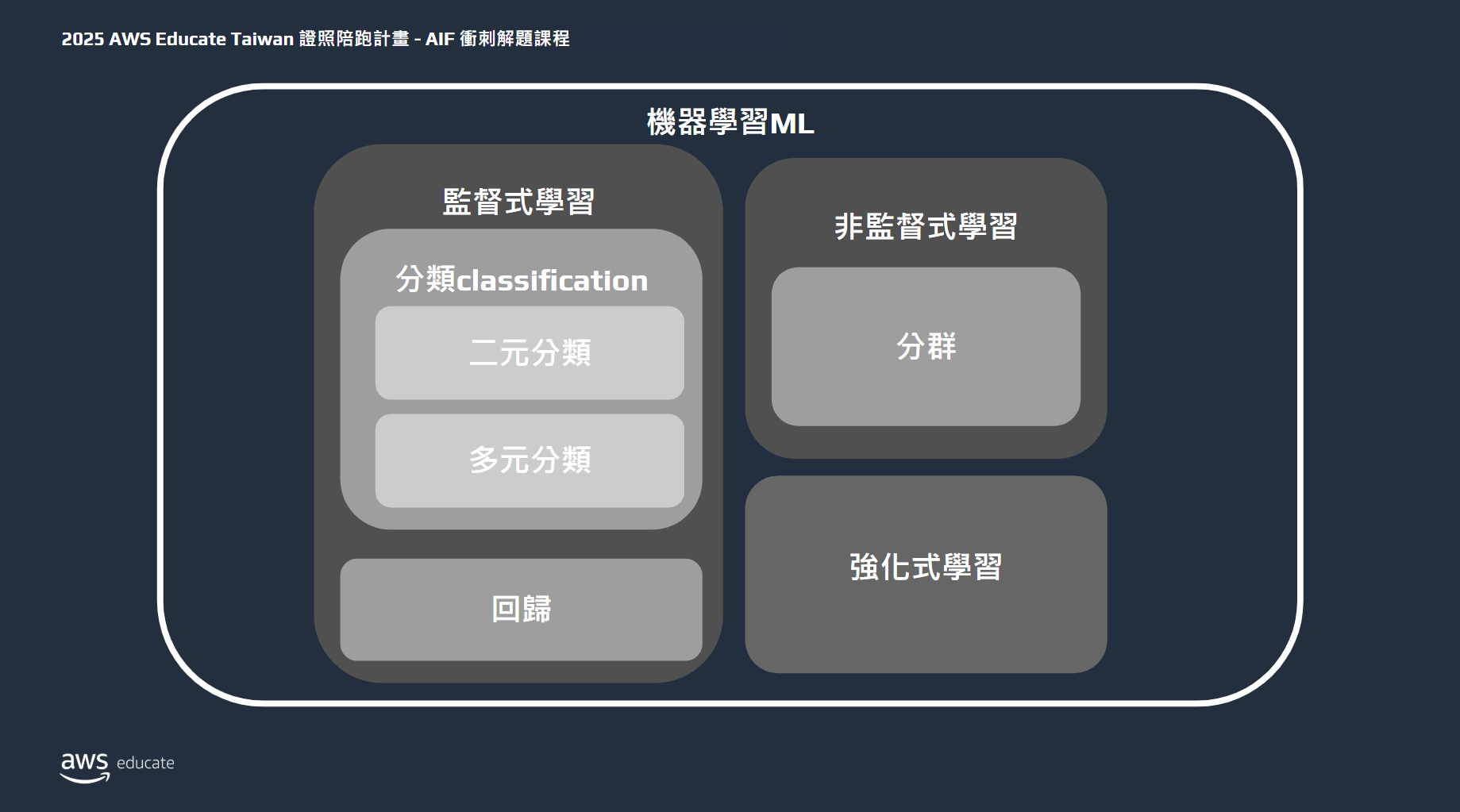
機器學習主要可分為以下類別:監督式學習、非監督式學習、半監督式學習和強化式學習。以下是各類型的詳細介紹:
1. 監督式學習(Supervised Learning)
監督式學習是指使用帶有標籤(label)的資料來訓練模型。模型學習輸入(features)與目標輸出(target)之間的關係,並用來預測新數據的結果。監督式學習可進一步分為兩大類:分類(Classification)和回歸(Regression)。
(1) 分類(Classification)
分類問題的目標是預測數據屬於哪個類別,通常適用於離散型輸出的情境,例如判斷一封郵件是否為垃圾郵件(Spam 或 Not Spam)。
a. 二元分類(Binary Classification)
- 目標變數只有兩種可能的類別(如 0 或 1、是或否、正面或負面)。
- 應用案例:
- 電子郵件垃圾過濾(Spam 或 Not Spam)
- 醫療診斷(是否患有某種疾病)
- 貸款核准(批准或拒絕)
b. 多元分類(Multiclass Classification)
- 目標變數有多個類別,但每個樣本只能屬於其中一個類別。
- 應用案例:
- 手寫數字辨識(0~9)
- 影像分類(貓、狗、馬等)
- 文章分類(科技、政治、娛樂)
(2) 回歸(Regression)
回歸問題的目標是預測連續數值(Continuous Values),適用於數值型輸出的情境,例如預測房價或股票價格。常見的回歸演算法有:
線性回歸(Linear Regression)
決策樹回歸(Decision Tree Regression)
支援向量回歸(Support Vector Regression, SVR)
隨機森林回歸(Random Forest Regression)
神經網絡回歸(Neural Network Regression)
應用案例:
- 房價預測(依據房屋大小、地點等)
- 銷售額預測(基於歷史數據)
- 天氣溫度預測
2. 非監督式學習(Unsupervised Learning)
非監督式學習指的是數據沒有標籤(沒有 target 變數),模型的目標是從數據中發掘潛在的模式或結構。
(1) 分群(Clustering)
分群的目標是將相似的數據點歸類在一起,這在資料探索與市場分析等應用中非常重要。
- 應用案例:
- 客戶分群(依據購買行為將顧客分成不同群體)
- 影像壓縮(將類似顏色的像素分組以減少存儲需求)
- 基因分析(根據 DNA 數據分類不同類型的生物)
3. 半監督式學習(Semi-Supervised Learning)
半監督式學習介於監督式學習與非監督式學習之間,指的是模型在訓練時同時使用少量的標註數據和大量的未標註數據。這種方法適用於標註成本高昂但未標註數據豐富的場景,如:
- 網頁分類(少量標註的網頁,大量未標註的網頁)
- 醫學影像分析(標註的醫學影像昂貴,但未標註的影像數量龐大)
常見技術包括:
- 自監督學習(Self-supervised Learning)
- 生成對抗網絡(GANs, Generative Adversarial Networks)
4. 強化式學習(Reinforcement Learning, RL)
強化式學習是一種透過試錯法(trial and error)學習的方式,換句話說就是透過一種基於獎勵與懲罰的學習方式,讓模型(代理人,Agent)透過與環境互動來學習最佳策略,以最大化累積的獎勵。其實這樣的學習方式就像一個孩子會因為做好家務而獲得父母的讚美,或者因為亂丟玩具而受到責備,久而久之,他就會學習哪些行為可以帶來正面的結果。
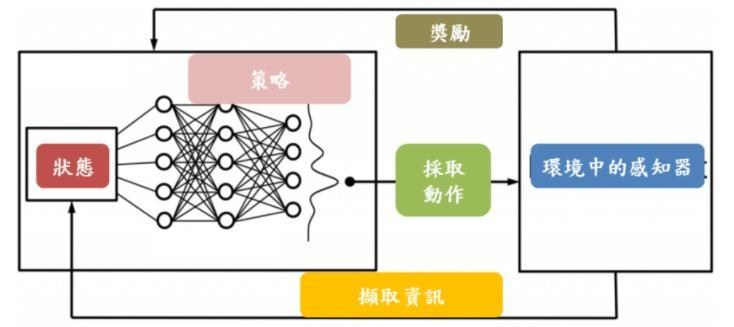
強化學習的關鍵概念與運作方式
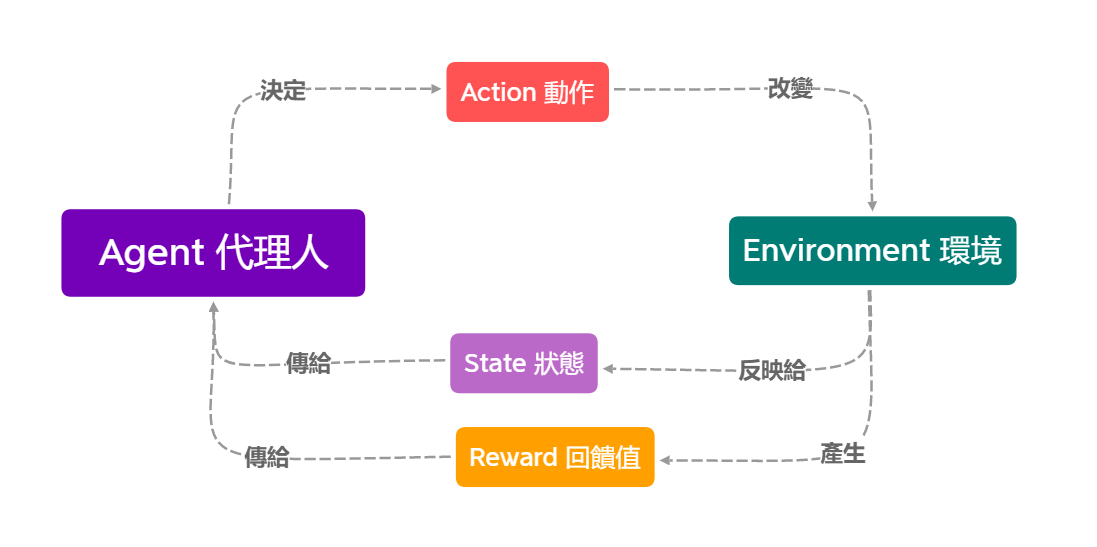
強化學習基於馬可夫決策過程(Markov Decision Process, MDP),代理程式根據當前狀態選擇行動,行動會影響環境的變化並導致新的狀態,環境則會提供對應的獎勵或懲罰。透過大量試錯,代理程式最終學會如何選擇最佳的行動策略,以最大化長期獎勵。 以下為此方法的關鍵概念:
- 代理程式(Agent):負責執行行動的學習系統,例如 AI 模型。
- 環境(Environment):代理程式所處的世界,包含規則、條件和變數,例如遊戲中的關卡或真實世界的交通環境。
- 動作(Action):代理程式在環境中可以採取的步驟,例如機器人行走的方向或遊戲角色的移動。
- 狀態(State):環境在某個時間點的情況,例如一台自駕車目前的位置、車流狀況等。
- 獎勵(Reward):代理程式執行動作後獲得的回饋,可以是正值(獎勵)或負值(懲罰)。
- 累積獎勵(Cumulative Reward):所有獎勵的總和,代理程式的目標是最大化累積獎勵。
- 應用案例:
- 遊戲 AI(如 AlphaGo、Dota 2 AI)
- 機器人控制(讓機器人學習如何走路、避障)
- 自動駕駛(學習如何根據環境做出駕駛決策)
Transfer Learning(遷移學習)
將一個領域上已訓練好的模型的知識,遷移到另一個相關但不同的領域上。這樣可以節省大量的時間與資源,因為你不需要從頭訓練模型,只需針對新任務進行微調(fine-tuning)。
考題範例
Q17
A company has petabytes of unlabeled customer data to use for an advertisement campaign. The company wants to classify its customers into tiers to advertise and promote the company’s products.Which methodology should the company use to meet these requirements?
- Supervised learning
- Unsupervised learning
- Reinforcement learning
- Reinforcement learning from human feedback (RLHF)
答案是 (B),因為這些資料是 unlabeled 的
Q7
A company is using domain-specific models. The company wants to avoid creating new models from the beginning. The company instead wants to adapt pre-trained models to create models for new,related tasks.
Which ML strategy meets these requirements?
- Increase the number of epochs.
- Use transfer learning.
- Decrease the number of epochs.
- Use unsupervised learning.
Q44
A company is developing a new model to predict the prices of specific items. The model performed well on the training dataset. When the company deployed the model to production, the model’s performance decreased significantly.
What should the company do to mitigate this problem?
- Reduce the volume of data that is used in training.
- Add hyperparameters to the model.
- Increase the volume of data that is used in training.
- Increase the model training time.
Q35
A company has terabytes of data in a database that the company can use for business analysis. The
company wants to build an AI-based application that can build a SQL query from input text that
employees provide. The employees have minimal experience with technology.
Which solution meets these requirements?
- Generative pre-trained transformers (GPT)
- Residual neural network
- Support vector machine
- WaveNet
員工技術經驗有限,但想用「自然語言」(例如:用英文輸入問題)來查詢資料。需要一個 AI 應用程式能夠:
- 將自然語言轉換成 SQL 查詢語句
- 讓非技術員工也能使用
這種應用最常見的模型就是 GPT(Generative Pre-trained Transformer)系列,像是 ChatGPT、Codex、Amazon Q Developer 背後的模型等。
B. Residual Neural Network (ResNet) 用於 圖像辨識 的深度學習模型,不適合處理語言或文字生成。
C. Support Vector Machine (SVM) 傳統的機器學習分類器,不具備生成 SQL 語句的能力,且對自然語言處理能力有限。
D. WaveNet 由 DeepMind 開發,用於語音合成(例如 Google Assistant 語音),與 SQL 或文字生成無關。