在準備生成式工作坊時接觸了不少相關的雲端服務,後來也陸續看了幾篇論文,但發現自己對於最基本的概念還沒有特別熟悉,於是就決定先認識背後原理。這篇文章就是希望記錄一下有關於 embedding 的知識。
什麼是 embedding(嵌入) ?
Embedding 是一種將高維度的離散數據(如文字、圖片或用戶行為)轉換為低維度的連續數值向量的方法,這些向量保留了原始數據的語義關係,使得機器學習模型能夠更有效地處理和理解這些數據。
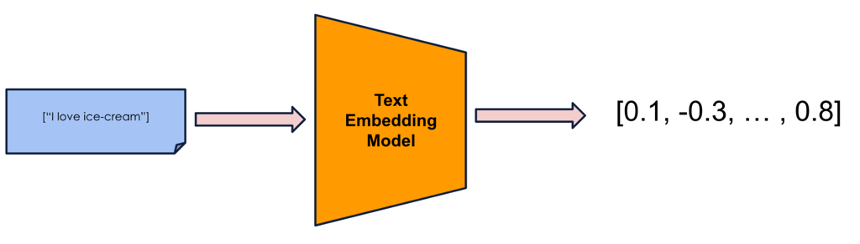
為什麼我們需要 embedding ? 以圖書館的管理員為例
我們可以拿圖書館的管理員當作例子,說明 embedding 是如何幫助模型進行分辨的。想像你是一位圖書館的管理員,任務是負責整理成千上萬本書,這時候如果你只是用書名來區分它們,就會很難找到相似主題的書。例如,《哈利波特》跟《魔戒》可能放在不同的地方,雖然它們其實都是奇幻小說。
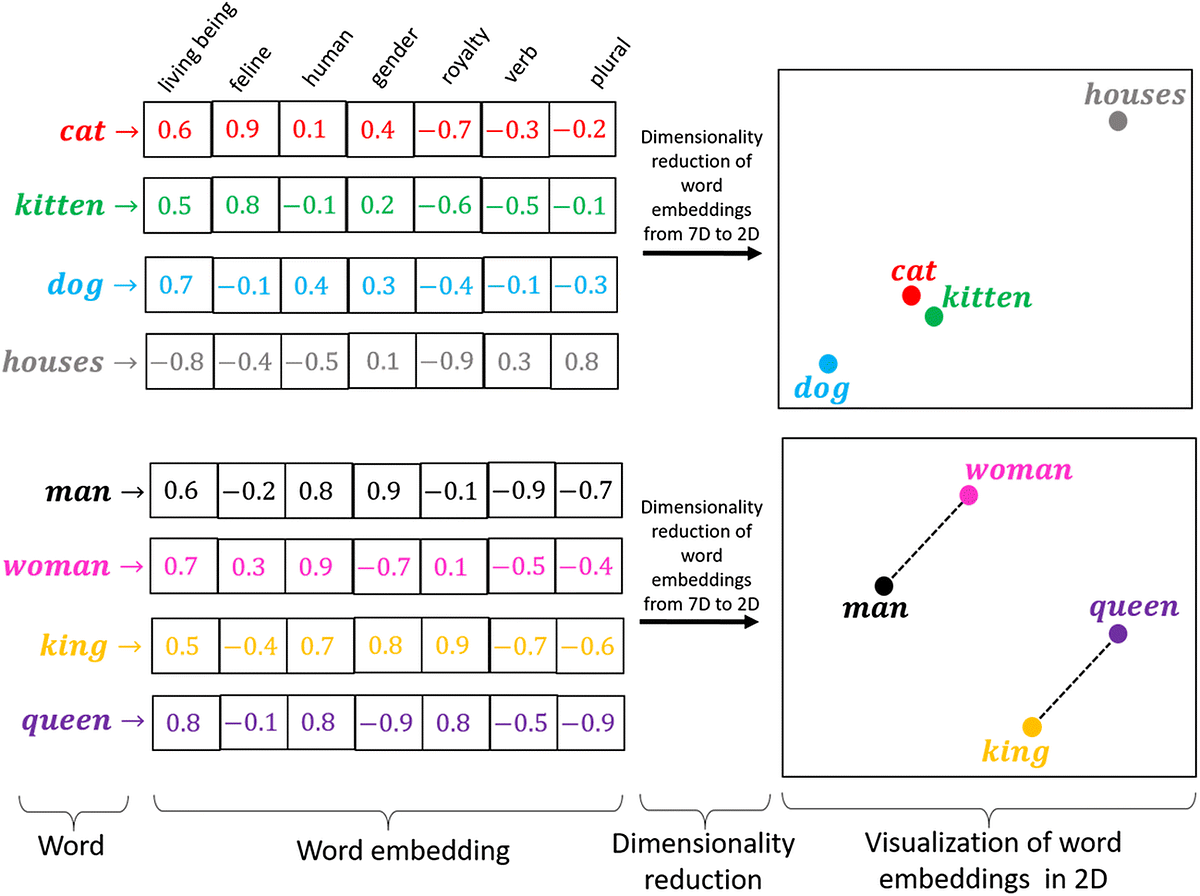
這時,你決定為每本書加上標籤,例如:「奇幻」、「冒險」、「魔法」、「戰鬥」。這些標籤可以讓你更快找到類似的書,而不只是根據書名來分類。而這就像 embedding,將「書」(高維度、離散的文字資訊)轉換成「標籤數據」(低維度、數值化的向量),讓機器能夠根據內容相似度來判斷書籍的關係。假設我們轉換的向量是四維,[w, x, y, z] 中的四個數值分別代表「奇幻」、「冒險」、「魔法」、「戰鬥」四種主題的符合程度,當數值越接近 1,則代表內容越符合該主題的書。以下舉例:
- 《哈利波特》→ [0.9, 0.8, 0.7, 0.6] (高度相關於奇幻、冒險、魔法)
- 《魔戒》→ [0.8, 0.9, 0.6, 0.7] (也是奇幻、冒險、魔法,但數值稍有不同)
- 《愛麗絲夢遊仙境》→ [0.7, 0.5, 0.8, 0.2] (更偏向童話,魔法比例較高,但戰鬥較少)
透過這些數值,就可以幫助圖書館管理員辨別哪些書的風格相近,即便他們書名大相逕庭。
各維度向量數值代表特徵嗎 ? embedding 模型其實是超大黑箱 !
目前針對 embedding 每個維度的向量意涵眾說紛紜,上述以圖書館的管理員為例之說明僅是幫助大家對於 embeddings 如何幫助搜索更有想像空間,事實上沒有人可以理解 Embedding 模型產生的向量值所代表的含意。
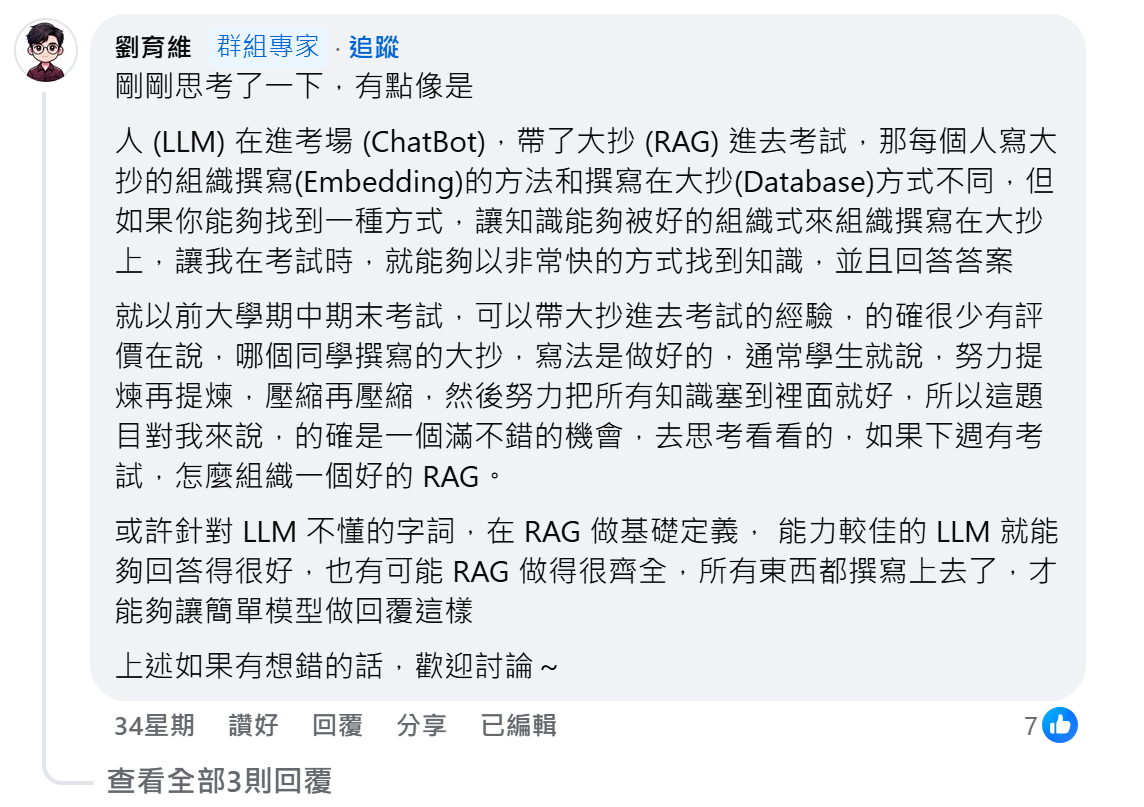
我們可以用比喻來理解多個模型在應用中的情況。假設 LLM 進入了 ChatBot 的考場,而這場考試允許攜帶大抄。在這個比喻中,大抄就是 RAG,實際上它代表了 embedding 方法與資料庫。就像每個學生的大抄會依據他們的讀書方式、理解能力與記憶方式而有所不同,內容、編排和組織方式也各不相同,LLM 的「大抄」也是如此。每個模型使用的 RAG 會根據其訓練方法與知識結構的不同而有所區別,影響其在考試中檢索和應對問題的能力。
因此,我們無法確定生成式領域中模型 embeddings 內容的具體含義,或者說它們代表著不同特徵的相似比例,因為這些向量的組織方式與數值並非以人類直觀的方式呈現。每個模型如何生成並利用這些向量,取決於其訓練過程與結構設計,這讓我們難以直接理解每個向量背後所代表的具體特徵。
如何透過向量做到語意關聯 ?
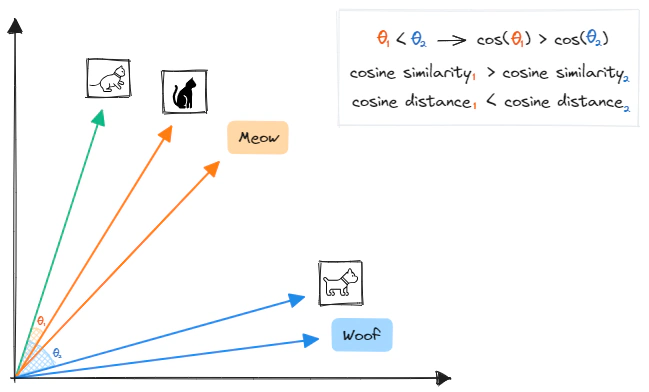
那這些向量又是如何保留語意的呢 ? 當我們獲得詞的向量後,可以通過計算向量之間的相似度來衡量語意關聯。常見的相似度度量方法有:
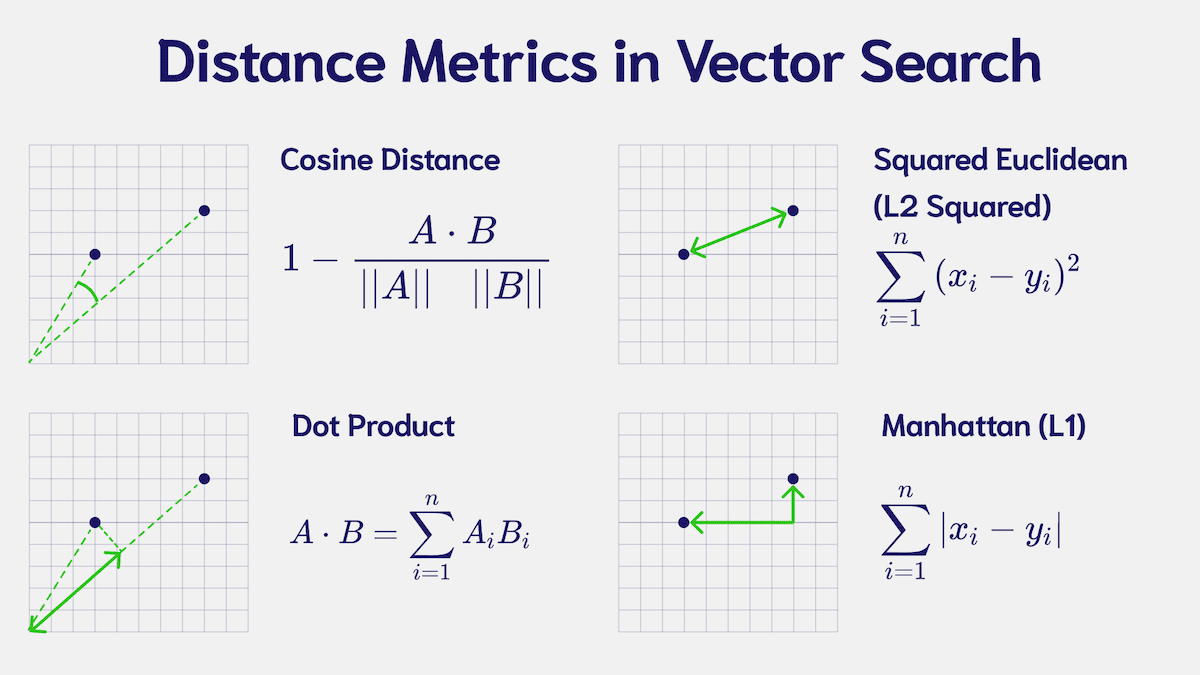
餘弦相似度 (Cosine Similarity)
餘弦相似度是一種衡量兩個向量在空間中方向相似度的方法,它專注於向量間的角度差異,而不是大小差異。這意味著即使兩個向量的長度(大小)不同,只要它們的方向相似,餘弦相似度會較高。
$$
\text{Cosine Similarity}(A, B) = \frac{A \cdot B}{|A| |B|}
$$
- 當兩個向量方向完全相同時,餘弦相似度的值為 1。
- 當兩個向量的方向完全相反時,餘弦相似度的值為 -1。
- 當兩個向量正交(沒有任何關聯)時,餘弦相似度的值為 0。
歐氏距離 (Euclidean Distance)
歐氏距離是衡量兩個向量之間的直線距離,即在向量空間中,兩點之間的最短距離。這個距離與向量的大小和方向都相關,較小的歐氏距離表示兩向量(或詞語)之間的相似度較高。
$$
\text{Euclidean Distance}(A, B) = \sqrt{(A_1 - B_1)^2 + (A_2 - B_2)^2 + \dots + (A_n - B_n)^2}
$$
embedding 如何生成 ?
文字 embedding
文字 embedding 的精隨在於將人類文字轉成 word vector,因為 word vector 他保留了原先文本數據特徵,也就是一段句子裡「字」、「詞」、「句」之間的意義。在這個部分主要有 One-Hot encoding 和 Word Embedding 兩種方式來建立向量。
淺層神經網絡學習
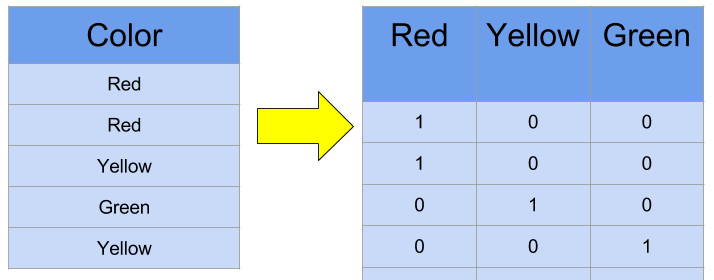
- One-Hot encoding
- 維度是詞數量,例如現在有 apple、banana 兩個單字,維度就是 2
- 當字詞庫越來越大時,每個詞的向量就會超長,導致實務上每一個 Word Vector 可能都會是好幾萬維的稀疏矩陣。
- 每一個 Word Vector 之間都是 Independent,無法體現上下文之間的語意相關
- Word Embedding
- 克服 One-Hot encoding 的缺點
- 將字詞轉換成可以投射到空間的向量
- 透過詞彙在空間的距離表示語法、語意相似度